
Database Indexing, performance and How It Works
Indexing in Database is a wide topic. Database indexing plays a important role in your query result performance. But like everything this too has a trade off. I know and assumed that you already worked with Indexing and you indexed your few field of your database table, But in this post I will explain a bit tho I’m not a good writer will try to finish within short. What is Indexing, How it works etc.
Indexing This is a silly question right? anyways lets give it a try with formal and informal way.
Indexing is a way of sorting a number of records on multiple fields. Creating an index on a field in a table creates another data structure which holds the field value, and pointer to the record it relates to. This index structure is then sorted, allowing Binary Searches to be performed on it. This index is obviously the non clustered one (no worries!, we will look into clustered and non-clustered index also). There is no need to create separate data structure for Clustered indexes since the original data is stored physically sorted based on it. seems complex? chill, come on
Simply An Index is a data structure that optimize searching and accessing the data. It’s like an index at the back of a book. When your database start to grow, the performance will be a concern. Hence, getting directly to a specific row in a large table in the least possible time is a priority. Now it’s seems easy, understand right? awesome.
Clustered and Non-Clustered Index
-
Clustered Index : Data in tables of a database need to be stored on a physical disk at the end of the day. It is important the way data is stored since data lookup is based on it. The way data is stored on physical disk is decided by an index which is known as Clustered index. Since data is physically stored only once , only one clustered index is possible for a DB table. Generally that’s the primary key of the table. That’s right. Primary key of your table is a Clustered index by default and data is stored physically based on it.
Points to be noted here :
- Here leaf nodes , contains the actual data pages of the underlying table.
- Only one clustered index on a table
- The physical order of the rows are same as the clustered index.
Note : You can change this though. You can create a primary key that is not clustered index but a non clustered one. However you need to define one clustered index for your table since physical storage order depends on it.
-
Non-Clustered Index : Non clustered indexes are normal indexes. They order the data based on the column we have created non clustered index on. Note since data is stored only once on the disk and there is just one column(or group of columns ) which can be used to order stored data on disk we cannot store the same data with ordering specified by non clustered index (that’s the job of clustered index). So new memory is allocated for non clustered indexes. These have the column on which it is created as the key of the data row and a pointer to the actual data row (which is ordered by clustered index - usually the primary key). So if a search is performed on this table based on the columns that have non clustered indexes then this new data set is searched (which is faster since records are ordered with respect to this column) and then the pointer in it is used to access the actual data record with all columns.
Points to be noted here :
- Here leaf nodes contains pointer to the actual data rows
- There can be more than one non-clustered index on a table
- The physical order of the rows are not same as the index order
How does it work
Firstly, let’s say we have a sample database table like below
| Field name | Data type | Size on disk |
|---|---|---|
| id (primary key) | Unsigned INT | 4 bytes |
| product_name | Char(100) | 100 bytes |
| product_line | Char(100) | 100 bytes |
| price | double | 8 bytes |
Field name Data type Size on disk id (Primary key) Unsigned INT 4 bytes firstName Char(50) 50 bytes lastName Char(50) 50 bytes emailAddress Char(100) 100 bytes
Note: Char was used in place of varchar to allow for an accurate size on disk value. This sample database contains five million rows and is UNINDEXED. The performance of several queries we will analyze now. These are a query using the id (a sorted key field) and one using the product_name (a non-key unsorted field).
Example 1 - sorted vs unsorted fields
Given our sample database of r = 10,000,000 records of a fixed size giving a record length of R = 204 bytes and they are stored in a table using the MyISAM engine which is using the default block size B = 1,024 bytes. The blocking factor of the table would be bfr = (B/R) = 1024/204 = 5 records per disk block. The total number of blocks required to hold the table is N = (r/bfr) = 10000000/5 = 2,000,000 blocks.
A linear search on the id field would require an average of N/2 = 1,000,000 block accesses to find a value, given that the id field is a key field. But since the id field is also sorted, a binary search can be conducted requiring an average of log2 2000000 = 20.934 = 20 block accesses. Instantly we can see this is a drastic improvement.
Now the product_name field is neither sorted nor a key field, so a binary search is impossible, nor are the values unique, and thus the table will require searching to the end for an exact N = 10,000,000 block accesses. It is this situation that indexing aims to correct.
Given that an index record contains only the indexed field and a pointer to the original record, it stands to reason that it will be smaller than the multi-field record that it points to. So the index itself requires fewer disk blocks than the original table, which therefore requires fewer block accesses to iterate through. The schema for an index on the product_name field is outlined below:
| Field name | Data type | Size on disk |
|---|---|---|
| product_name | Char(100) | 100 bytes |
(record pointer) Special 4 bytes
Note: Pointers in MySQL are 2, 3, 4 or 5 bytes in length depending on the size of the table.
Example 2 - Indexing
Given our sample database of r = 10,000,000 records with an index record length of R = 54 bytes and using the default block size B = 1,024 bytes. The blocking factor of the index would be bfr = (B/R) = 1024/54 = 18 records per disk block. The total number of blocks required to hold the index is N = (r/bfr) = 10000000/18 = 555555.56 blocks.
Now a search using the product_name field can utilize the index to increase performance. This allows for a binary search of the index with an average of log2 555555.56 = 19.08 = 19 block accesses. To find the address of the actual record, which requires a further block access to read, bringing the total to 19 + 1 = 20 block accesses, a far cry from the 10,000,000 block accesses required to find a product_name match in the non-indexed table.
Data-Structure used in Index
There are 4 types of data structure used in database indexing e.g B-Tree, Hash, R-Tree, Bitmap Indexing. We will discuss about most commonly used two are B-Tree and Hash Indexing.
B-Tree Indexes:
These are most common types of indexes. It’s kind of self balancing tree. It stores data in an ordered manner so that retrievals are fast. These are useful since they provide insertion, search and deletion in logarithmic time. Consider below image. If we need rows with data less that 100 all we need are notes to the left of 100.
Time Complexity : O(log n)
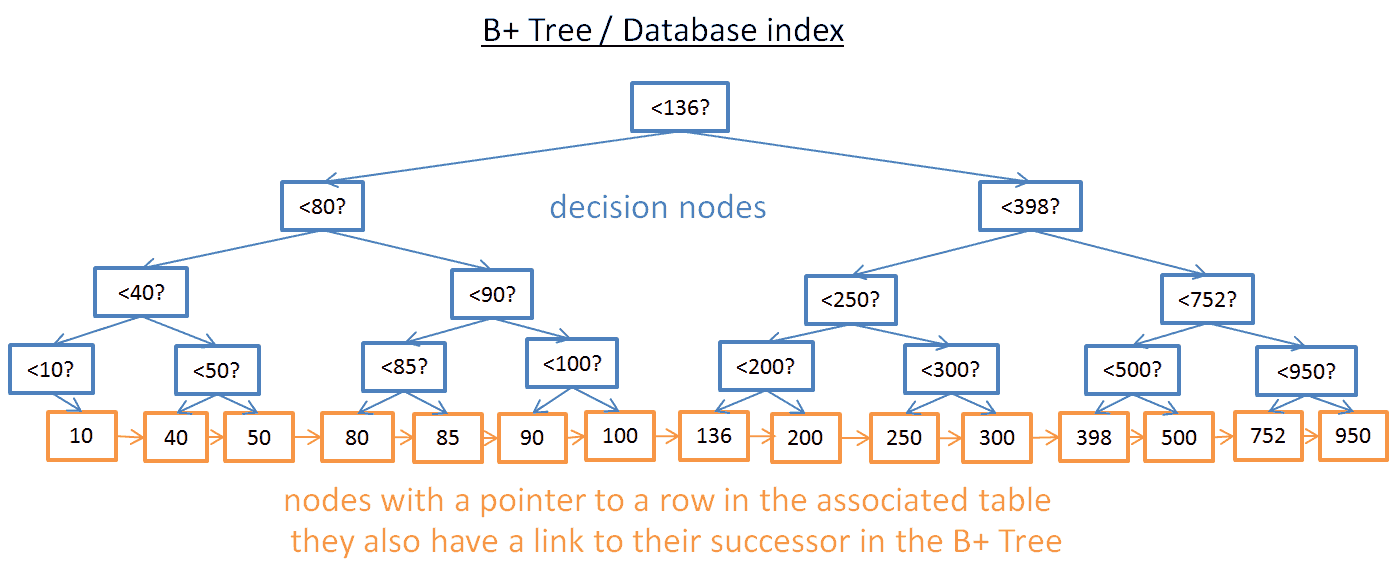
Photo collected from internet
Hash Indexes
As we know how a HashMap. Key here would be derived from columns that are used to create a index (non clustered index to be precise). Value would be pointer to the actual table row entry. They are good for equality lookups like get rows of data of all customer whose age is 24. But what happens when we need a query like set of data of customer with age greater than 24. Hash index does not work so go in this case. Hash indexes are just good for equality lookups.
Time Complexity : O(n)
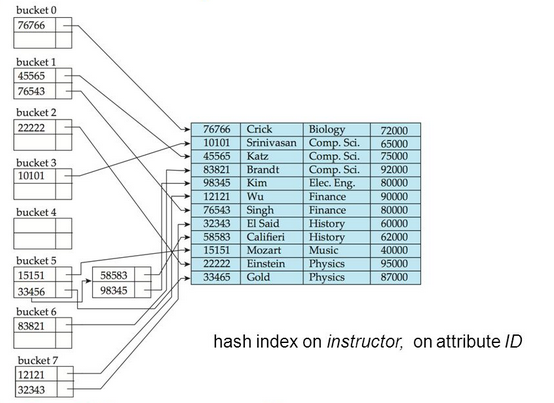
Photo collected from internet
Note: Hash indexes to perform no better than B-tree indexes, and the index size and build time for hash indexes is much worse. Furthermore, hash index operations are not presently WAL-logged, so hash indexes might need to be rebuilt with REINDEX after a database crash. For these reasons, hash index use is presently discouraged.
Points to be note
-
Don’t use function in where clause which takes column parameter as index. Functions render indexes useless. Functions are like blackbox and database optimized does not know about it’s relationship with argument the function takes. So instead of using the index it will perform full table scan. e.g
create index user_name_idx on user(name);select * from user where name='zaman'; --uses indexselect * from user where lower(name)='arif';–cannot use index
- If you do have a concatenated index then choose the column order so that mulitple sql queries (of you usecases) can use it. e.g
select * from user where name='zaman';–sql1select * from user where name='arif' and age=36;– sql2create index user_name_idx on user(name, age);–correct-
create index user_name_idx on user(age, name);–incorrect (sql1 cannot use this) -
Don’t use like expressions in your where clause which starts with a wildcard. it will be of no use even the column is indexed. e.g
create index user_name_idx on user(name);select * from user where name like '%rif';– will be very slowselect * from user where name like 'zam%';–will be fast as it used prefix on index
-
Always index for equality first (vrs lets say a range)
create index user_name_idx1 on user(birth_date, name);–slowercreate index user_name_idx2 on user( name, birth_date);–fasterselect * from user where name='Zaman' and birth_date >= TO_DATE('2012-08-20')
- Always check if covered index as possible. This prevents actual table access since you get all the data in index only. So lets say you have a table with columns A-Z. Also lets say you have an index on column B and your query is something like -
select A from table where B='XYZ'- Query looks good and it will use our index defined on column B and speed up the query time in the process but for each hit in btree leaf of index it will need to access actual table row to get A.
- Now consider you have index on (B,A). Since your where clause has B this index will be picked up. However in this case once entries are located we already have value of A which we need to find. So this will avoid lookup of actual table row.
- This obviously depends on your use case. None the less it’s important to consider this use case.
To know more about Database Indexing visit here Indexing and Tuning